Cluster-Analyse ist ein einfaches und effektives Werkzeug, das im Geschäftsumfeld verwendet wird. Es hilft dabei, komplizierte quantitative oder manchmal qualitative Daten mit detaillierten Modellierungsmethoden besser zu verstehen. Im Gegensatz zu anderen Arten von Analysen ist sein Hauptzweck nicht, Gründe aufzuzeigen oder zu beweisen; es ist ein Hilfsmittel, um besser zu enthüllen, was passiert.
In diesem Artikel wird zur eingehenden Untersuchung der Cluster-Analyse zunächst erläutert, was eine Cluster-Analyse ist. Anschließend wird erläutert, welche Methoden/Arten Sie verwenden können, um diese Analyse durchzuführen. Schließlich können Sie aus dem Abschnitt Häufig gestellte Fragen genauere Informationen erhalten.
Was ist eine Cluster-Analyse?
Die Cluster-Analyse ist eine multivariate Datenverarbeitungsmethode, die zur Darstellung von Statistiken verwendet wird. Sie zielt darauf ab, Entitäten zu kategorisieren oder, genauer gesagt, zu clustern.
Sie dient als grundlegender und entscheidender Schritt in der statistischen Datenanalyse sowie im Data Mining. Es ist jedoch auch möglich, sie in verschiedenen Bereichen einzusetzen. Insbesondere kann die Cluster-Analyse im Data Mining sowohl qualitative als auch quantitative Merkmale angeben, was ihre Flexibilität zeigt. Deshalb verwenden Unternehmen die Cluster-Analyse immer als Teil ihrer Entscheidungsmechanik.
Der Algorithmus der Cluster-Analyse ist recht einfach. Er erstellt sichtbare Muster, indem er ähnliche Entitäten zusammen gruppiert. Mit dieser Funktion ist er jedoch weit davon entfernt, eine detaillierte Analyseart zu sein. Auf der anderen Seite hat auch die Bereitstellung genauer Daten einen wichtigen Platz hier.
Je mehr Daten für das Clustering geeignet sind, desto effektiver wird ein Clustering-Muster gebildet. Daher ist es eine gute Idee, die Methoden und Programme auszuwählen, die für Ihr Ziel am besten geeignet sind, wenn Sie eine Cluster-Analyse durchführen.
Arten der Clusteranalyse
Die Wahl des richtigen Clustering-Algorithmus kann ein wenig wie Trial-and-Error sein. Aber wenn es einen soliden mathematischen Grund gibt, einen gegenüber den anderen zu bevorzugen, kann das vernünftig sein. Und das Wichtige hier ist, dass das, was für einen Datensatz wie Magie funktionieren könnte, bei einem anderen komplett scheitern könnte.
Eine Vielzahl von Methoden für die Clusteranalyse werden Ihnen unten präsentiert, von denen jede ihren eigenen Aspekt und Ansatz mitbringt. Es ist wie die Wahl des richtigen Werkzeugs für die Arbeit und herauszufinden, welches mit Ihrem Datensatz funktioniert. Nun, die vier bekanntesten Typen werden Ihnen mit Beispielen für die Clusteranalyse präsentiert:
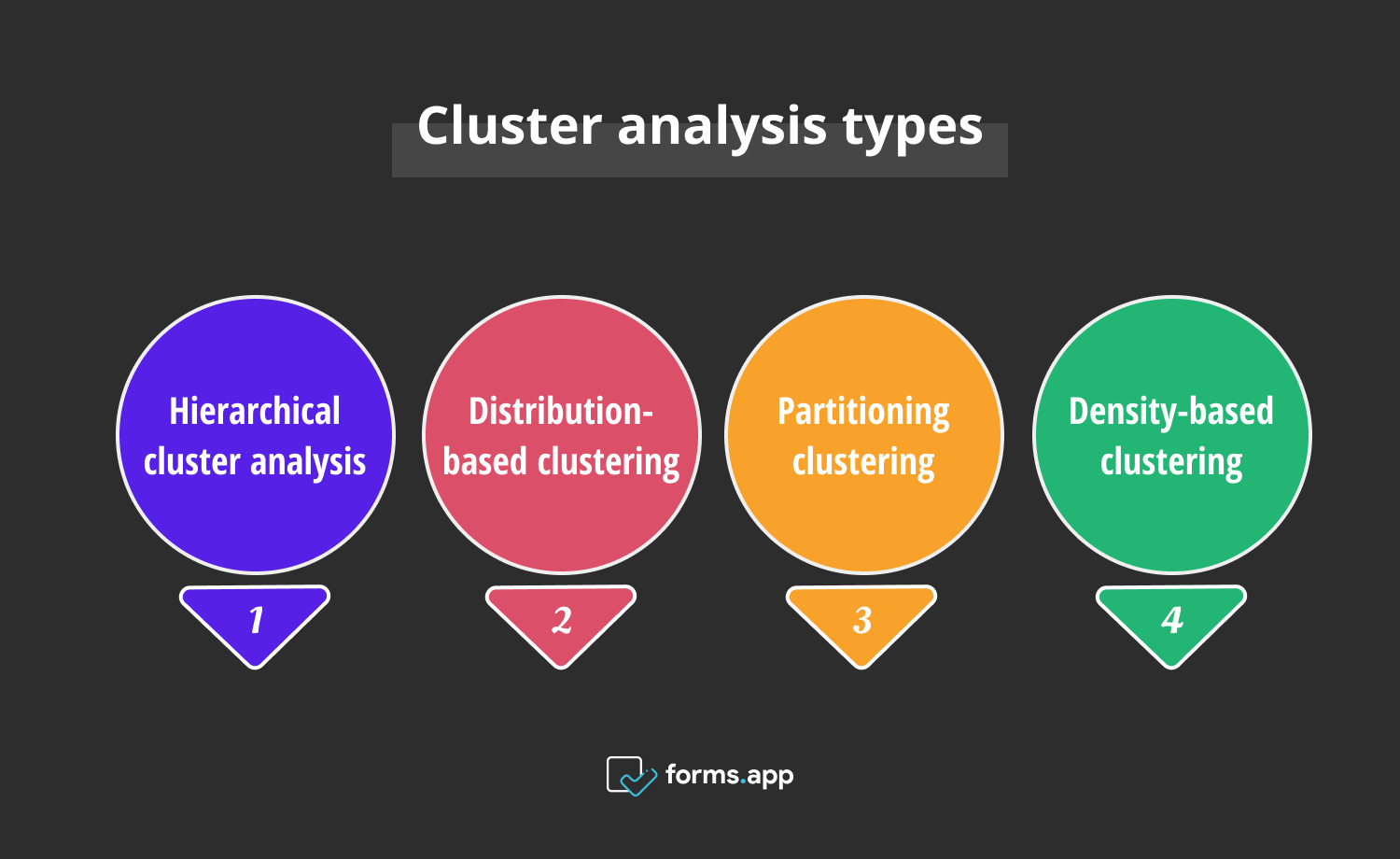
Arten der Clusteranalyse
Hierarchische Clusteranalyse
Bei dieser Methode ordnet der Algorithmus die Clusterung der bereitgestellten Datenobjekte in eine hierarchische Reihenfolge ein. Die Bildung von Clustern erfolgt durch Starten von einem einzigen Cluster und Aufteilen in separate Cluster.
Die Reihenfolge der Hierarchie zwischen diesen Clustern kann je nach Zweck Ihrer Klassifizierung und Ihrer Modellierungsmethode variieren. Sie können hauptsächlich zwei verschiedene Ansätze für die hierarchische Clusterung verwenden:
- Agglomerative Methode: Es handelt sich um einen Bottom-Up-Prozess, der mit einem einzelnen Objekt beginnt und Clustergruppen daraus bildet.
- Divisive Ansatz: Es handelt sich um einen Top-Down-Prozess, der mit Objekten im selben Cluster beginnt und Clustergruppen durch Aufteilen bildet.
#Beispiel für hierarchische Clusteranalyse
Stellen Sie sich vor, ein Technologieunternehmen bringt ein neues Smart-Home-Gerät auf den Markt. Das Unternehmen möchte hierarchische Clusteranalyse verwenden, um zu verstehen, wie potenzielle Kunden auf dieses neue Produkt reagieren werden. Daten wie Alter, Einkommen, Bildungsniveau, etc., werden für die Analyse gesammelt.
Hierarchische Analyse beginnt entsprechend Cluster zu erstellen. Zum Beispiel wird ein Cluster wie junge Menschen und solche mit hohem Einkommen gebildet, und diese Gruppe kann genau die Zielgruppe sein, die Sie suchen.
Verteilungsbasiertes Clustering
Dieses Clustering-Modell zeigt die Verteilung von zusammenhängenden Datenentitäten auf dem Graphen. Gaussian Mixture Models sind ein typisches Beispiel für diese Art. Ihr Anwendungsbereich besteht darin, Strukturen, die miteinander verbunden sind, mit komplexen Strukturen leichter zu clustern.
#Beispiel für verteilungsbasiertes Clustering
Nehmen wir an, ein Internetanbieter möchte Muster des Kundenabwanderungsverhaltens verstehen, um dagegen intervenieren zu können. Dazu sollte zunächst ein Datensatz mit Informationen wie allgemeiner oder spezifischer Kundenzufriedenheit, Präferenzen für Internetpakete, Verpflichtungsgebühren und Antworten vorhanden sein.
Dann verwenden Sie den verteilungsbasierten Clustering-Algorithmus und warten darauf, dass er das Muster zwischen diesen Werten aufdeckt. Wenn zum Beispiel die Verkaufsrate in einer Gruppe, die häufig kontaktiert wird, um Internetverpflichtungen zu erneuern, niedrig ist, dann ist dies und ähnliche Muster ein Beispiel für aktuelle und zukünftige Abwanderung.
Partitionierendes Clustering
Im Gegensatz zu verteilungsbasiertem Clustering teilt die Partitionierung Datenentitäten in nicht-überlappende Abschnitte auf. Jeder dieser Abschnitte wird dann zu einem Cluster. Diese Cluster können für einen bestimmten Zweck voneinander getrennt werden. Um eine solche Partitionierung durchzuführen, wird am häufigsten die K-Means-Methode verwendet.
- K-Means-Clustering: K-Means-Clustering sortiert Ihren Datensatz in vordefinierte Cluster. Der Algorithmus platziert zufällig Clusterzentren und beginnt, Datenentitäten um diese Zentren zu sortieren. Dann wird der Durchschnitt dieser Zentren genommen und ein neues Zentrum erstellt. Dieser Prozess kann mehrmals wiederholt werden, wodurch nicht überlappende Cluster entstehen.
#Beispiel für partitionierendes Clustering
Stellen Sie sich ein Geschäft in einem Einzelhandelsszenario vor, das Schwierigkeiten mit seiner Marketingstrategie hat. Die Entscheidung für partitionierendes Clustering ist der erste Schritt in der Marktforschung. Die Machine-Learning-Algorithmen werden Cluster wie Kundengruppen und Marktsegmente entsprechend vorgegebener Partitionen identifizieren.
Die resultierenden Kundenmuster helfen dem Unternehmen, bessere Initiativen für den Zielmarkt zu ergreifen. Zum Beispiel kann das Geschäft bei einem Kundenprofil mit hohen Ausgaben seine Marketingaktivitäten stärken, indem es Treueprogramme und Aktionen für diese Kundengruppe anbietet.
Dichtebasiertes Clustering
Dichtebasiertes Clustering deckt ähnliche Gruppen auf, indem es die Dichte von Datenpunkten identifiziert. Insbesondere unterscheidet es sich von anderen Typen dadurch, dass es vermeidet, die Cluster zu einer bestimmten Form oder Größe zu machen, sondern eine bestimmte Anzahl von Clustern zu erstellen. In dieser Hinsicht ist es nützlich in Fällen, in denen Datenentitäten eine unregelmäßige Anordnung aufweisen, wenn sie einen Cluster bilden.
#Beispiel für dichtebasiertes Clustering
Angenommen, ein Unternehmen versucht, neue Geschäfte zu eröffnen und möchte Hotspots von Kunden identifizieren. Es möchte die Qualität des neuen Einzelhandelsgeschäfts verbessern, indem es einen dichtebasierten Clustering-Algorithmus verwendet.
Der Algorithmus kann durch die Unterscheidung von Gebieten mit intensivem Kundenfluss, Bevölkerungsdemografie und Kaufverhalten dieser Bevölkerung geeignete Standorte identifizieren. Auf diese Weise haben Geschäftsinhaber wertvolle Daten, die sie bei Entscheidungen über die Eröffnung des Geschäfts nutzen können.
Häufig gestellte Fragen zum Clusteranalyse
Die häufigsten Fragen zur Clusteranalyse beziehen sich auf wann und wie man welche Clustering-Methode verwendet. Neue Benutzer können manchmal Verwirrung bei der Interpretation von Clustern erleben. Deshalb zielen die hier gesammelten Fragen darauf ab, wichtige Nuancen der Interpretation effektiv aufzuschlüsseln und Sie auf die Datenanalyse vorzubereiten.
Die vier gängigsten Arten der Clusteranalyse sind die hierarchische Clusteranalyse, das Verteilungsclustering, das Partitionierungsclustering und das dichtebasierte Clustering. Obwohl sie alle mehr oder weniger denselben Zweck verfolgen, unterscheiden sich ihre Clustering-Prozesse voneinander.
Selbstorganisierende Karten, graphenbasierte Methoden und gitterbasierte Methoden sind ebenfalls wertvolle Methoden, die Sie bei der Erkennung von Clustermustern verwenden können.
Wie bekannt, werden bei der Clusteranalyse keine Daten gesammelt. Stattdessen wird ein nützliches Modell erstellt, indem Ihre Daten mit dem Clustering-Algorithmus in Teile und Gruppen aufgeteilt werden. Daher sollten Sie die Daten für die Clusteranalyse selbst vorbereiten und dabei einige Faktoren beachten.
- Suchen Sie zunächst die Daten, die für Ihren Zweck geeignet sind, und erstellen Sie eine vollständige Datenbank mit allen Details.
- Standardisieren Sie die Daten entsprechend der Skala, nach der Sie sie auswerten wollen.
- Passen Sie Ihre Daten an das von Ihnen verwendete Clustering-Programm an.
- Schließlich lassen Sie das Programm die Daten mit Hilfe des Clustering-Algorithmus klassifizieren.
Zwar sticht die Clusteranalyse auf den ersten Blick als quantitativer Analysetyp hervor, doch zeigen erfolgreiche Algorithmen und eine gut aufbereitete Datenvorlage, dass sie auch in der qualitativen Analyse eingesetzt werden kann.
Die Analyse der Clustering-Ergebnisse ist ebenso wichtig wie die Erstellung und Verarbeitung der Daten. Sie können Gruppen (farbig, gruppiert oder geformt) mit der Leichtigkeit, die die Modellierung bietet, visuell untersuchen. Die Auswertung der numerischen Daten nach der Methode, mit der Sie Ihre Modellierung erstellt haben, ist der nächste Schritt.
Auf diese Weise bestimmen Sie die Merkmale jeder Clustergruppe. Wenn Ihre Daten auch qualitative Merkmale enthalten, vergessen Sie nicht, die Musterbeziehungen entsprechend zu bewerten. Als Ergebnis dieser Analyseschritte werden Sie in der Lage sein, die Clusteranalyse für Ihren Entscheidungsprozess zu nutzen.
Nein, Clusterstichproben und Clusteranalysen sind nicht dasselbe. Cluster Sampling ist ein Verfahren, das in der Phase der Datenerhebung eingesetzt wird. Es wird verwendet, um eine große Gruppe von Populationen nach dem Zufallsprinzip zu beproben. Bei der Clusteranalyse ist sie nicht obligatorisch. Andererseits ist die Clusteranalyse eine Datenanalysemethode zur Ermittlung ähnlicher Muster und deren Gruppierung.
Schlussfolgerung
Insgesamt zeigt die Clusteranalyse ihre Kraft, um Muster mithilfe verschiedener Modellierungstechniken aufzudecken. Ihre hohe Dimensionalität ist ein starker Aspekt davon. Dieser Artikel versucht zu zeigen, dass die Clusteranalyse im Marketing und Daten-Mining für Unternehmen von Vorteil ist. Ob es sich um qualitative Erkenntnisse oder quantitative Vorhersagen handelt, die Clusteranalyse enthüllt die Beziehung zwischen ihnen durch leistungsstarke Datenexploration.
Das heißt, moderne Unternehmen profitieren von dieser Art der Analyse, um Trends zu verfolgen und Korrelationen aufzudecken, die auf den ersten Blick nicht sichtbar sind. Sie sollten also die Clusteranalyse verstehen und davon profitieren, um Ihr Unternehmen in einer Welt zu verbessern, in der Daten so wertvoll sind wie Gold.
Atakan ist ein Inhaltsverfasser bei forms.app. Er recherchiert gerne in verschiedenen Bereichen wie Geschichte, Soziologie und Psychologie. Er beherrscht Englisch und Koreanisch. Seine Expertise liegt in der Datenanalyse, Datenarten und -methoden.
Beginnen Sie noch heute mit forms.app
- Unbegrenzte Ansichten
- unbegrenzte Anzahl von Fragen
- unbegrenzte Benachrichtigungen

Wie man bedingte Fragen in Typeform verwendet

